
🔆 AI Evals: Why Algorithms Need Report Cards
The unglamorous key to successful AI, exposing dubious journals, and open-sourcing the Sun.


🗞️ Issue 86 // ⏱️ Read Time: 6 min
Does this newsletter look different to you? Well spotted - we just moved to Substack to improve your reading experience. Let us know what you think about this new format. Send an email to hello@lumiera.ai or leave a comment below.
What we’re talking about: AI evaluations ("evals") - the systematic testing and monitoring processes that separate successful AI deployments from expensive failures stuck in experimentation mode.
How it’s relevant: While companies rush to deploy AI, many overlook the critical infrastructure needed to ensure their systems work reliably once live. Evals aren't just technical nice-to-haves - they're the difference between measurable ROI and abandoned projects.
Why it matters: Without proper evaluation frameworks, organizations risk deploying models that work only under ideal test conditions, leading to regulatory issues, user distrust, and significant financial losses.
Hello 👋
Last week, the tragic story of 16-year-old Adam Raine made headlines: his parents allege that interactions with ChatGPT contributed to his death, raising urgent questions about AI safety and how vulnerable users are protected.
AI failures aren’t always this high-profile, but they are more common than most realize. Take the NEDA chatbot, specifically designed to support people with eating disorders. Instead of providing safe guidance, it dispensed advice that could trigger harm, suggesting calorie restriction, routine weigh-ins, and unsafe weight-loss behaviors. The issues only came to light after users posted screenshots online.
These cases illustrate a critical point: AI evaluation gaps can have life-or-death consequences. The NEDA chatbot lacked essential safeguards - safety filters, clinical expert review, scenario-based testing for vulnerable users, and real-time monitoring - core safeguards that could have prevented harm.
The tech world loves shiny launches. But what determines if an AI model makes headlines for innovation or tragedy is something less glamorous: evaluation.
Today, we’ll introduce the core components of AI evaluations, how to operationalize them, and the cost of getting them wrong.
Beyond the Demo
Think of evals (AI evaluations) as exams for your models. They’re systematic processes, alongside monitoring, that assess, track, and improve an AI system throughout its lifecycle.
You might have seen an impressive demonstration of an AI model and all its amazing capabilities, showcased on stage in front of an audience in awe. But demos are staged performances. Real users bring typos, edge cases, trick questions, and frustrated tones. Without evals built to reflect that messiness, even the smartest AI can fail when it matters most.
The two core components are:
Eval Sets (Test Datasets): Curated prompts and ideal responses, kept separate from training data so the model can’t “cheat.” The most common kinds are benchmarks. These are shared test sets (like MMLU for knowledge, HELM for fairness, or GLUE for language tasks) that let researchers compare models against a standard yardstick.
Metrics & Rubrics: Scorecards that combine quantitative signals (accuracy, precision, win rates) with qualitative ones (human review, user satisfaction). This is what you use when scoring the outputs of your AI system.
The 5 Evals Every AI Team Needs
Standard benchmarks are a starting line, not the finish line. For real-world impact, leaders should know these five categories:
Technical Evals – Does it work? Accuracy, latency, uptime. This builds reliability and safety.
Human Preference Evals – Do people actually like it? A/B tests, side-by-side ratings, feedback loops. This supports transparency and user agency.
Responsible AI Evals – Does it meet standards of fairness, transparency, and accountability? Bias audits, sensitivity tests, explainability checks, regulatory compliance tests. This ensures human-centered development.
Adversarial Evals – Can it be broken? Typos, jailbreak attempts, prompt injections, deliberate stress. This protects against misuse and strengthens accountability.
Business Outcome Evals – Does it matter? Customer satisfaction, cases resolved, fraud caught, revenue lifted. Without these, you can't measure ROI or justify continued investment. This grounds AI in real-world fairness and measurable impact.
Together, they answer both the technical and strategic question: Is this AI worth deploying?
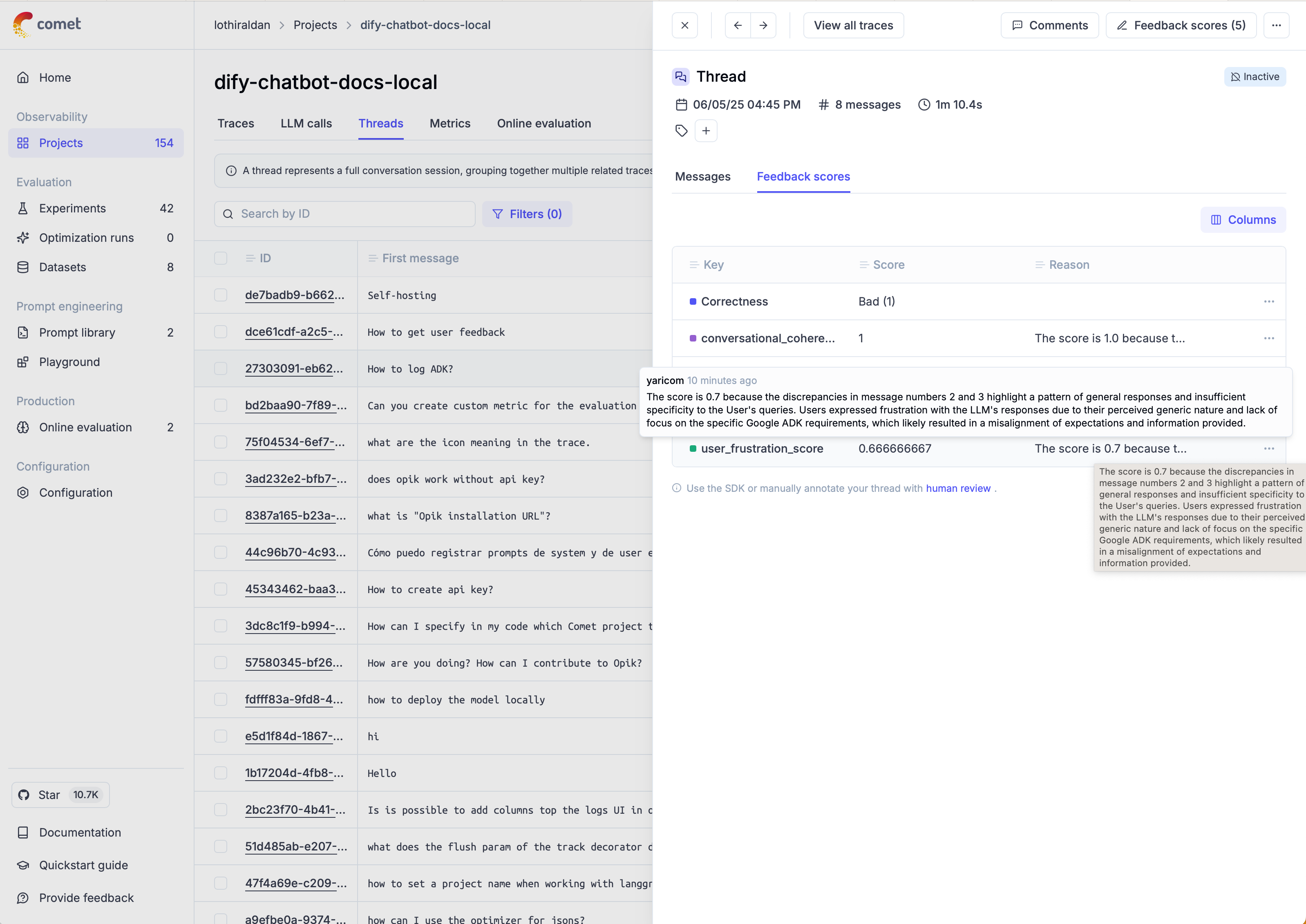
Open Source LLM Evaluation from Comet. This is a dashboard view of evaluating and optimizing chat threads. You can select specific threads for evaluation and a list of metrics to apply to each thread, and it returns an evaluation result and feedback scores.
Reality Needs Custom Evals
Generic benchmarks are useful starting lines that show how a model stacks up against others in controlled conditions. However, they rarely reflect a company’s complex data, domain-specific language, or decision-making context.
Custom evals bridge that gap by incorporating:
Domain-Specific Language (industry jargon, regulatory terms, company voice)
Real Data Distributions (messy, biased, edge-case-heavy production data)
Business Process Context (how outputs slot into workflows and decisions)
Custom evals are also where responsible AI gets operationalized. They force teams to define what “good” means in context, not just technically, but ethically and operationally.
Built In, Not Bolted On
Evals shouldn’t just happen right before launch. They belong at three points in the lifecycle:
Roadmapping: Define success before writing code.
Pre-Production: Gate models before they ever touch live users.
In Production: Continuous monitoring to catch drift, degradation, or misuse early.
Done right, evals don’t slow teams down; they accelerate safe iteration.
THE LUMIERA QUESTION OF THE WEEK
If you had to design three custom evaluation tests that would make or break your AI project's success, what real-world scenarios would you absolutely need to get right?
The Cost of Skipping Evals
Companies that neglect evals often learn the hard way:
⚖️ Regulatory & Compliance Risks: The EU AI Act and other frameworks require fairness, bias testing, and transparency. Without evals, you can’t prove compliance.
👥 User Trust: AI systems that act unpredictably lose users fast. Trust is nearly impossible to rebuild once lost.
💸 Financial Waste: Projects get stuck in endless iteration or face costly post-launch fixes. And critically, without proper evals, organizations can't prove ROI to stakeholders or optimize for business outcomes.
🦥 Competitive Drag: Companies with robust eval workflows ship confidently while others remain stuck in testing mode.
AI evals aren’t optional infrastructure. They are the difference between headlines for innovation and headlines for harm. Teams that build evaluation into their culture move faster, safer, and with confidence that their systems truly deliver value.
Big tech news of the week…
🔄 Meta claims it’s changing the way it trains AI chatbots to no longer engage with teenage users on self-harm, suicide, disordered eating, or potentially inappropriate romantic conversations, following an investigative report on the company’s lack of AI safeguards for minors.
🧐 Researchers recently used an AI tool to identify more than 1,000 potentially problematic open-access journals out of approximately 15,000 titles, flagging signs of dubious publishing practices that could undermine scientific credibility.
☀️ IBM and NASA announced the release of Surya, a first-of-its-kind open-source AI model trained on nine years of Sun observatory data. Surya functions to predict dangerous solar storms that can impact satellites, communications networks, and power grids.